Building a Modern Vulnerability Management Program: A Strategic Framework for CISOs


Most vulnerability management programs fail not because of technical shortcomings, but because of structural ones. Organizations fall into a predictable pattern: deploy scanners, generate reports, pressure engineering teams to remediate. The result is just as predictable. Alert fatigue sets in, relationships with development teams turn adversarial, and security debt piles up faster than anyone can pay it down.
Breaking this cycle means rethinking vulnerability management as a strategic business function, not just a technical compliance exercise.
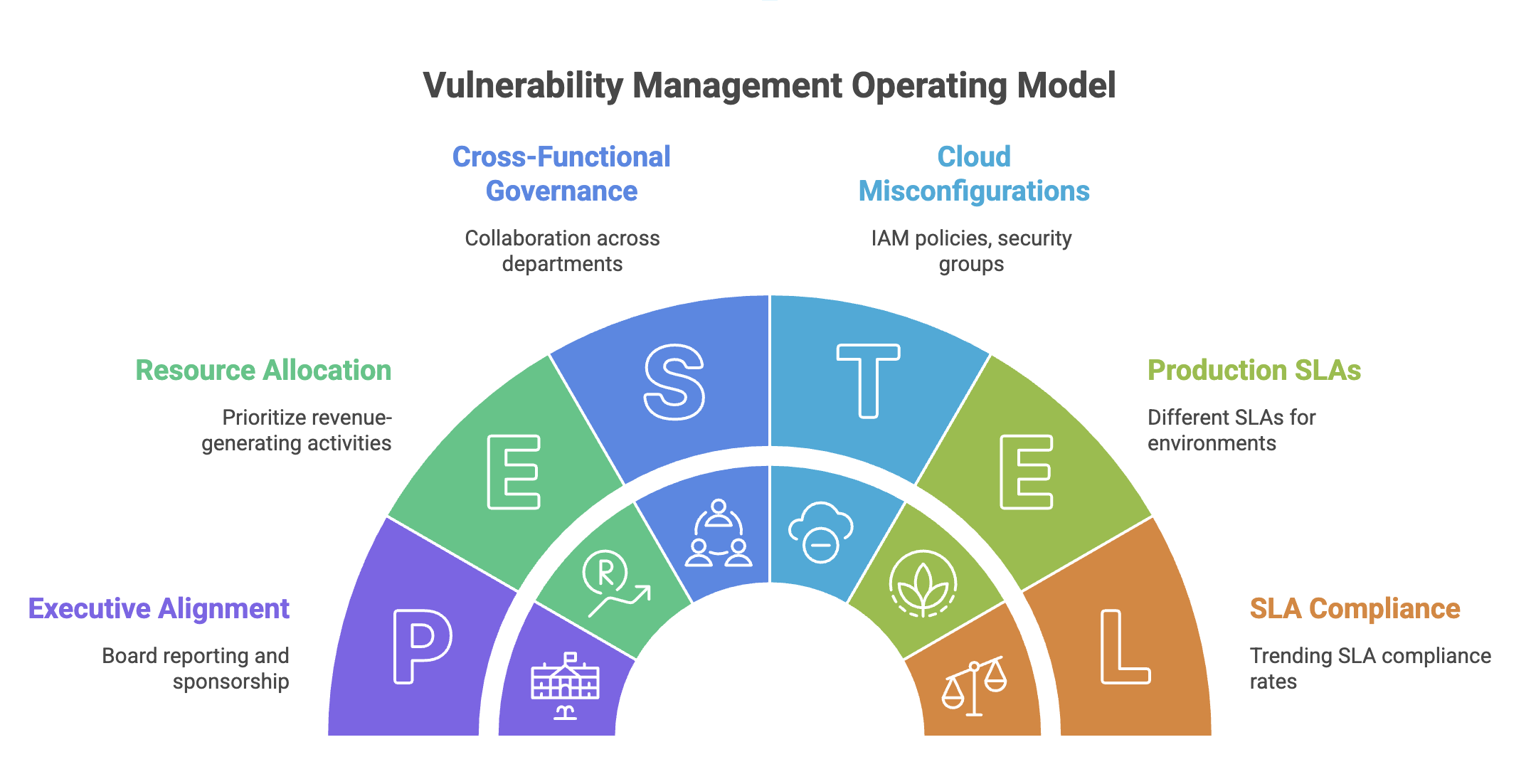
A Three-Tier Operating Model
Effective programs operate across three distinct tiers, each with different stakeholders, metrics, and cadences.
At the strategic tier, focus on executive alignment and cross-functional governance. Board reporting should move beyond raw vulnerability counts to metrics that actually convey business risk: mean time to remediate (MTTR) for critical findings broken down by environment, percentage of crown jewels with open high-severity findings, and trending SLA compliance rates. Aim for MTTR benchmarks of 7 days for critical findings in production, 30 days for high, and 90 days for medium. Report quarter-over-quarter trends rather than point-in-time snapshots. The trajectory tells a more honest story than any single number. Without executive sponsorship, vulnerability management will always lose the resource battle to revenue-generating priorities.
At the tactical tier, recognize that vulnerabilities are not all the same. Application-layer findings require different remediation workflows, ownership models, and tooling than infrastructure vulnerabilities. In cloud environments, this distinction goes even further: misconfigurations in IAM policies, overly permissive security groups, and exposed storage buckets represent a different risk category than CVEs in running workloads. Track cloud misconfigurations separately with their own SLAs. An S3 bucket with public read access deserves a 24-hour remediation window regardless of whether a scanner flagged it as high or medium.
Production environments need fundamentally different SLAs than corporate systems or development sandboxes. Structure your program around these distinctions rather than applying blanket policies that end up satisfying no one.
At the operational tier, concentrate your remediation energy on crown jewels, the assets whose compromise would cause real business damage. In cloud-native environments, this means prioritizing workloads with access to sensitive data stores, services with elevated IAM roles, and anything sitting in the runtime path of customer transactions. Maintain a current inventory with clear ownership tags. If you cannot answer "who owns this resource" within minutes, your asset management is not good enough to support effective vulnerability management.
Reframe Vulnerabilities as Technical Debt
The most important shift a CISO can make is repositioning vulnerability management as a technical debt problem rather than a security problem. That unpatched library sticks around because upgrading it means refactoring dependent code. That legacy system stays vulnerable because modernization lost out to feature development when the roadmap was set.
This reframing does two things. First, it creates natural alignment with engineering leadership who are already pushing for infrastructure investment and system modernization. Second, it changes the organizational conversation from "security is slowing us down" to "we are collectively managing system health and technical risk." Track vulnerability remediation alongside other technical debt metrics. Teams already measuring code quality and dependency freshness should fold security findings into the same dashboards and sprint planning conversations.
Shift Left Through Proactive Hygiene
The highest-leverage remediation happens before vulnerabilities ever reach production.
Establish a quarterly image refresh cycle, a mandatory cadence for rebuilding base containers and golden images. This single practice wipes out the long tail of low and medium findings that eat up tracking overhead without actually reducing risk. Organizations running quarterly refreshes typically see 40-60% reduction in total open findings just by eliminating drift. Measure image age as a leading indicator. Any base image older than 90 days should trigger automatic review.
Apply CIS benchmarks rigorously to base images, stripping out unnecessary packages and disabling unused services at the source. For cloud workloads, extend this discipline to infrastructure-as-code templates. Your Terraform modules and CloudFormation stacks should bake in security controls so misconfigured resources simply cannot deploy. When your foundation ships secure by default, engineering teams inherit good security posture instead of bolting it on later under deadline pressure.
Identity as the New Perimeter
In cloud environments, identity vulnerabilities often carry more risk than traditional CVEs. An overprivileged service account or a developer with standing admin access to production creates attack surface that no container scan will ever catch.
Build identity hygiene into your vulnerability management program. Track metrics like percentage of human identities with MFA enforced (target: 100%), number of service accounts with admin privileges (target: as few as possible, each one justified), and age of unused credentials (target: disable after 90 days of inactivity). Review IAM policies quarterly for privilege creep. Roles accumulate permissions over time as teams add access for one-off tasks and never clean it up.
Treat identity findings with the same urgency as critical CVEs. A service account key that has not been rotated in 18 months, or a role with wildcard permissions, should generate alerts and remediation tickets with defined SLAs.
Validate Through Adversary Simulation
Scanners tell you what is vulnerable. Red team exercises show you what is actually exploitable. These are fundamentally different questions, and mixing them up leads to wasted remediation effort.
Run regular adversary simulations designed specifically to test lateral movement pathways. Can an attacker pivot from a compromised development environment into production? Does that medium-severity finding in the corporate network open an unexpected path to crown jewels? Can a compromised developer laptop escalate through SSO and cloud console access to reach production data? Does the network segmentation documented in your architecture diagrams actually stop the traversal it claims to?
These exercises deliver ground truth that scanner output alone cannot provide. Track time to detect and time to contain during exercises to benchmark your operational response capabilities alongside your preventive controls.
Treat Vulnerability Data as an Enterprise Asset
Modern vulnerability management generates massive amounts of both structured and unstructured data: scanner outputs, cloud security posture findings, architecture documentation, compensating controls buried in wikis, remediation tracking in ticketing systems, exception approvals scattered across email threads. The information exists, but it lives in silos across systems and teams.
Build a data architecture that pulls structured scanner data together with unstructured context from documentation and workflow tools. Correlate findings across tools. That container vulnerability becomes a lot more urgent when you combine it with CNAPP data showing the workload has a public IP and an attached role with S3 access. This kind of integration lets you answer questions that were previously unanswerable: Which vulnerabilities have documented compensating controls? What is the actual exposure when you account for network segmentation? Which findings have been stuck past SLA because of blocked dependencies?
Measure data quality alongside remediation metrics. What percentage of findings have assigned owners? How many are blocked waiting on dependency upgrades? What are the false positive rates by scanner? Without this visibility, you cannot tell the difference between a remediation failure and a process failure.
Codify Zero-Day Response
Every mature program needs a documented, rehearsed playbook for critical zero-day response. When the next Log4j or MOVEit drops, your team should be executing a known process rather than making it up on the fly.
The playbook should spell out escalation paths, stakeholder communication templates, criteria for emergency patching versus compensating controls, and rollback procedures. Include cloud-specific response steps. How quickly can you identify all affected resources across accounts and regions? Do you have pre-approved change windows for emergency deployments? Can you push WAF rules or network controls as a stopgap while patches are tested?
Run tabletop exercises quarterly to stress-test the process. Measure time from vulnerability disclosure to complete organizational visibility. If you cannot inventory your Log4j exposure within 4 hours, closing that gap matters more than most items sitting in your remediation backlog.
The Bottom Line
The most effective vulnerability management programs treat security findings as one piece of overall technical health rather than an isolated compliance checkbox. This framing makes sustainable resource allocation possible, keeps engineering relationships productive, and builds risk reduction that compounds over time instead of piling up as unaddressed debt.



